Principles of Concurrency, Race Condition, Operating System Concerns, Process Interaction, Competition among Processes for Resources, Cooperation among Processes by Sharing, Cooperation among Processes by Communication, Requirements for Mutual Exclusion
In a single-processor multiprogramming system, processes are interleaved in time to
yield the appearance of simultaneous execution. Even though actual
parallel processing is not achieved, and even though there is a certain amount of
overhead involved in switching back and forth between processes, interleaved execution
provides major benefits in processing efficiency and in program structuring.
In a multiple-processor system, it is possible not only to interleave the execution of
multiple processes but also to overlap them
At first glance, it may seem that interleaving and overlapping represent fundamentally
different modes of execution and present different problems. In fact, both
techniques can be viewed as examples of concurrent processing, and both present
the same problems. In the case of a uniprocessor, the problems stem from a basic
characteristic of multiprogramming systems: The relative speed of execution of
processes cannot be predicted. It depends on the activities of other processes, the
way in which the OS handles interrupts, and the scheduling policies of the OS. The
following difficulties arise:
1. The sharing of global resources is fraught with peril. For example, if two processes
both make use of the same global variable and both perform reads and writes on
that variable, then the order in which the various reads and writes are executed is
critical.An example of this problem is shown in the following subsection.
2. It is difficult for the OS to manage the allocation of resources optimally. For example,
process A may request use of, and be granted control of, a particular I/O
channel and then be suspended before using that channel. It may be undesirable
for the OS simply to lock the channel and prevent its use by other processes; indeed
this may lead to a deadlock condition.
3. It becomes very difficult to locate a programming error because results are
typically not deterministic and reproducible
All of the foregoing difficulties present themselves in a multiprocessor system
as well, because here too the relative speed of execution of processes is unpredictable.
A multiprocessor system must also deal with problems arising from the simultaneous
execution of multiple processes. Fundamentally, however, the problems
are the same as those for uniprocessor systems. This should become clear as the discussion
proceeds.
A Simple Example
void echo()
{
chin = getchar();
chout = chin;
putchar(chout);
}
This procedure shows the essential elements of a program that will provide a character
echo procedure; input is obtained from a keyboard one keystroke at a time.
Each input character is stored in variable chin. It is then transferred to variable
chout and sent to the display. Any program can call this procedure repeatedly to
accept user input and display it on the user’s screen.
Now consider that we have a single-processor multiprogramming system supporting
a single user. The user can jump from one application to another, and each
application uses the same keyboard for input and the same screen for output. Because
each application needs to use the procedure echo, it makes sense for it to be
a shared procedure that is loaded into a portion of memory global to all applications.
Thus, only a single copy of the echo procedure is used, saving space.
The sharing of main memory among processes is useful to permit efficient and
close interaction among processes. However, such sharing can lead to problems.
1. Process P1 invokes the echo procedure and is interrupted immediately after
getchar returns its value and stores it in chin. At this point, the most recently
entered character, x, is stored in variable chin.
2. Process P2 is activated and invokes the echo procedure, which runs to conclusion,
inputting and then displaying a single character, y, on the screen.
3. Process P1 is resumed. By this time, the value x has been overwritten in chin
and therefore lost. Instead, chin contains y, which is transferred to chout
and displayed.
Thus, the first character is lost and the second character is displayed twice. The
essence of this problem is the shared global variable, chin. Multiple processes have
access to this variable. If one process updates the global variable and then is interrupted,
another process may alter the variable before the first process can use its
value. Suppose, however, that we permit only one process at a time to be in that procedure.
1. Process P1 invokes the echo procedure and is interrupted immediately after
the conclusion of the input function. At this point, the most recently entered
character, x, is stored in variable chin.
2. Process P2 is activated and invokes the echo procedure. However, because P1 is
still inside the echo procedure, although currently suspended, P2 is blocked from
entering the procedure. Therefore, P2 is suspended awaiting the availability of
the echo procedure.
3. At some later time, process P1 is resumed and completes execution of echo.The
proper character, x, is displayed.
4. When P1 exits echo, this removes the block on P2. When P2 is later resumed,
the echo procedure is successfully invoked.
This example shows that it is necessary to protect shared global variables (and
other shared global resources) and that the only way to do that is to control the code
that accesses the variable. If we impose the discipline that only one process at a time
may enter echo and that once in echo the procedure must run to completion before
it is available for another process, then the type of error just discussed will not
occur.
This problem was stated with the assumption that there was a single-processor,
multiprogramming OS.The example demonstrates that the problems of concurrency
occur even when there is a single processor. In a multiprocessor system, the same
problems of protected shared resources arise, and the same solution works. First, suppose
that there is no mechanism for controlling access to the shared global variable:
1. Processes P1 and P2 are both executing, each on a separate processor. Both
processes invoke the echo procedure.
2. The following events occur; events on the same line take place in parallel:
Process P1
Process P2
•
•
chin = getchar();
•
•
chin = getchar();
chout = chin;
chout = chin;
putchar(chout);
•
•
putchar(chout);
•
•
The result is that the character input to P1 is lost before being displayed, and
the character input to P2 is displayed by both P1 and P2. Again, let us add the
capability of enforcing the discipline that only one process at a time may be in echo.
1. Processes P1 and P2 are both executing, each on a separate processor. P1 invokes
the echo procedure.
2. While P1 is inside the echo procedure, P2 invokes echo. Because P1 is still inside
the echo procedure (whether P1 is suspended or executing), P2 is blocked from
entering the procedure. Therefore, P2 is suspended awaiting the availability of
the echo procedure.
3. At a later time, process P1 completes execution of echo, exits that procedure,
and continues executing. Immediately upon the exit of P1 from echo, P2 is resumed
and begins executing echo.
In the case of a uniprocessor system, the reason we have a problem is that an
interrupt can stop instruction execution anywhere in a process. In the case of a multiprocessor
system, we have that same condition and, in addition, a problem can be
caused because two processes may be executing simultaneously and both trying to
access the same global variable. However, the solution to both types of problem is
the same: control access to the shared resource.
Race Condition
A race condition occurs when multiple processes or threads read and write data
items so that the final result depends on the order of execution of instructions in the
multiple processes. Let us consider two simple examples.
As a first example, suppose that two processes, P1 and P2, share the global
variable a. At some point in its execution, P1 updates a to the value 1, and at some
point in its execution, P2 updates a to the value 2.Thus, the two tasks are in a race to
write variable a. In this example the “loser” of the race (the process that updates
last) determines the final value of a.
For our second example, consider two process, P3 and P4, that share global
variables b and c, with initial values b = 1 and c = 2. At some point in its execution,
P3 executes the assignment b = b + c, and at some point in its execution, P4
executes the assignment c = b + c. Note that the two processes update different
variables. However, the final values of the two variables depend on the order in
which the two processes execute these two assignments. If P3 executes its assignment
statement first, then the final values are b = 3 and c = 5. If P4 executes its
assignment statement first, then the final values are b = 4 and c = 3.
Operating System Concerns
What design and management issues are raised by the existence of concurrency?
1. The OS must be able to keep track of the various processes.
2. The OS must allocate and deallocate various resources for each active process.
At times, multiple processes want access to the same resource.These resources
include
- Processor time
- Memory
- Files
- I/O devices
3. The OS must protect the data and physical resources of each process against unintended
interference by other processes. This involves techniques that relate to
memory, files, and I/O devices.
4. The functioning of a process, and the output it produces, must be independent
of the speed at which its execution is carried out relative to the speed of other
concurrent processes.
Process Interaction
• Processes unaware of each other: These are independent processes that are
not intended to work together. The best example of this situation is the multiprogramming
of multiple independent processes. These can either be batch
jobs or interactive sessions or a mixture. Although the processes are not working
together, the OS needs to be concerned about competition for resources.
For example, two independent applications may both want to access the same
disk or file or printer. The OS must regulate these accesses.
• Processes indirectly aware of each other: These are processes that are not necessarily
aware of each other by their respective process IDs but that share access
to some object, such as an I/O buffer. Such processes exhibit cooperation
in sharing the common object.
• Processes directly aware of each other: These are processes that are able to
communicate with each other by process ID and that are designed to work
jointly on some activity. Again, such processes exhibit cooperation.
Competition among Processes for Resources
Concurrent processes come
into conflict with each other when they are competing for the use of the same resource.
In its pure form, we can describe the situation as follows. Two or more processes
need to access a resource during the course of their execution. Each process is unaware
of the existence of other processes, and each is to be unaffected by the execution
of the other processes. It follows from this that each process should leave the
state of any resource that it uses unaffected. Examples of resources include I/O devices,
memory, processor time, and the clock.
There is no exchange of information between the competing processes. However,
the execution of one process may affect the behavior of competing processes.
In particular, if two processes both wish access to a single resource, then one process
will be allocated that resource by the OS, and the other will have to wait. Therefore,
the process that is denied access will be slowed down. In an extreme case, the
blocked process may never get access to the resource and hence will never terminate
successfully.
In the case of competing processes three control problems must be faced.
First is the need for mutual exclusion. Suppose two or more processes require
access to a single nonsharable resource, such as a printer. During the course of
execution, each process will be sending commands to the I/O device, receiving status
information, sending data, and/or receiving data. We will refer to such a
resource as a critical resource, and the portion of the program that uses it a critical
section of the program. It is important that only one program at a time be allowed
in its critical section. We cannot simply rely on the OS to understand and enforce
this restriction because the detailed requirements may not be obvious. In the case
of the printer, for example, we want any individual process to have control of the
printer while it prints an entire file. Otherwise, lines from competing processes will
be interleaved.
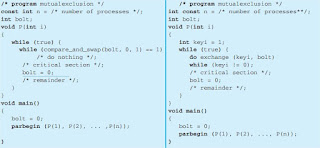
/* PROCESS 1 */
void P1
{
while (true) {
/* preceding code /;
entercritical (Ra);
/* critical section */;
exitcritical (Ra);
/* following code */;
}
}
/* PROCESS 2 */
void P2
{
while (true) {
/* preceding code */;
entercritical (Ra);
/* critical section */;
exitcritical (Ra);
/* following code */;
}
}
..........
/* PROCESS n */
void Pn
{
while (true) {
/* preceding code */;
entercritical (Ra);
/* critical section */;
exitcritical (Ra);
/* following code */;
}
}
The enforcement of mutual exclusion creates two additional control problems.
One is that of deadlock. For example, consider two processes, P1 and P2, and two resources,
R1 and R2. Suppose that each process needs access to both resources to
perform part of its function. Then it is possible to have the following situation: the
OS assigns R1 to P2, and R2 to P1. Each process is waiting for one of the two resources.
Neither will release the resource that it already owns until it has acquired
the other resource and performed the function requiring both resources. The two
processes are deadlocked.
A final control problem is starvation. Suppose that three processes (P1, P2, P3)
each require periodic access to resource R. Consider the situation in which P1 is in
possession of the resource, and both P2 and P3 are delayed, waiting for that resource.
When P1 exits its critical section, either P2 or P3 should be allowed access to
R. Assume that the OS grants access to P3 and that P1 again requires access before
P3 completes its critical section. If the OS grants access to P1 after P3 has finished,
and subsequently alternately grants access to P1 and P3, then P2 may indefinitely be
denied access to the resource, even though there is no deadlock situation.
Control of competition inevitably involves the OS because it is the OS that allocates
resources. In addition, the processes themselves will need to be able to express
the requirement for mutual exclusion in some fashion, such as locking a
resource prior to its use. Any solution will involve some support from the OS, such
as the provision of the locking facility. The mutual exclusion
mechanism in abstract terms. There are n processes to be executed concurrently.
Each process includes (1) a critical section that operates on some resource Ra, and
(2) additional code preceding and following the critical section that does not involve
access to Ra. Because all processes access the same resource Ra, it is desired that
only one process at a time be in its critical section. To enforce mutual exclusion, two
functions are provided: entercritical and exitcritical. Each function
takes as an argument the name of the resource that is the subject of competition.
Any process that attempts to enter its critical section while another process is in its
critical section, for the same resource, is made to wait.
It remains to examine specific mechanisms for providing the functions
entercritical and exitcritical. For the moment, we defer this issue while
we consider the other cases of process interaction.
Cooperation among Processes by Sharing
The case of cooperation by
sharing covers processes that interact with other processes without being explicitly
aware of them. For example, multiple processes may have access to shared variables
or to shared files or databases. Processes may use and update the shared data without
reference to other processes but know that other processes may have access to
the same data. Thus the processes must cooperate to ensure that the data they share
are properly managed. The control mechanisms must ensure the integrity of the
shared data.
Because data are held on resources (devices, memory), the control problems
of mutual exclusion, deadlock, and starvation are again present. The only difference
is that data items may be accessed in two different modes, reading and writing, and
only writing operations must be mutually exclusive.
However, over and above these problems, a new requirement is introduced:
that of data coherence. As a simple example, consider a bookkeeping application in
which various data items may be updated. Suppose two items of data a and b are to
be maintained in the relationship a b.That is, any program that updates one value
must also update the other to maintain the relationship.
P1:
a = a + 1;
b = b + 1;
P2:
b = 2 * b;
a = 2 * a;
If the state is initially consistent, each process taken separately will leave the
shared data in a consistent state.
a = a + 1;
b = 2 * b;
b = b + 1;
a = 2 * a;
At the end of this execution sequence, the condition a b no longer holds. For
example, if we start with a = b = 1, at the end of this execution sequence we have a
4 and b 3. The problem can be avoided by declaring the entire sequence in each
process to be a critical section.
Thus we see that the concept of critical section is important in the case of cooperation
by sharing. The same abstract functions of entercritical and
exitcritical can be used here. In this case, the argument
for the functions could be a variable, a file, or any other shared object. Furthermore,
if critical sections are used to provide data integrity, then there may be no
specific resource or variable that can be identified as an argument. In that case, we can think of the argument as being an identifier that is shared among concurrent
processes to identify critical sections that must be mutually exclusive.
Cooperation among Processes by Communication
In the first two cases
that we have discussed, each process has its own isolated environment that does not
include the other processes. The interactions among processes are indirect. In both
cases, there is a sharing. In the case of competition, they are sharing resources without
being aware of the other processes. In the second case, they are sharing values,
and although each process is not explicitly aware of the other processes, it is aware
of the need to maintain data integrity. When processes cooperate by communication,
however, the various processes participate in a common effort that links all of
the processes. The communication provides a way to synchronize, or coordinate, the
various activities.
Typically, communication can be characterized as consisting of messages of
some sort. Primitives for sending and receiving messages may be provided as part of
the programming language or provided by the OS kernel.
Because nothing is shared between processes in the act of passing messages,
mutual exclusion is not a control requirement for this sort of cooperation. However,
the problems of deadlock and starvation are still present. As an example of deadlock,
two processes may be blocked, each waiting for a communication from the
other. As an example of starvation, consider three processes, P1, P2, and P3, that exhibit
the following behavior. P1 is repeatedly attempting to communicate with either
P2 or P3, and P2 and P3 are both attempting to communicate with P1. A
sequence could arise in which P1 and P2 exchange information repeatedly, while P3
is blocked waiting for a communication from P1. There is no deadlock, because P1
remains active, but P3 is starved.
Requirements for Mutual Exclusion
1. Mutual exclusion must be enforced: Only one process at a time is allowed into
its critical section, among all processes that have critical sections for the same
resource or shared object.
2. A process that halts in its noncritical section must do so without interfering with
other processes.
3. It must not be possible for a process requiring access to a critical section to be delayed
indefinitely: no deadlock or starvation.
4. When no process is in a critical section, any process that requests entry to its critical
section must be permitted to enter without delay.
5. No assumptions are made about relative process speeds or number of processors.
6. A process remains inside its critical section for a finite time only.
There are a number of ways in which the requirements for mutual exclusion
can be satisfied. One way is to leave the responsibility with the processes that wish
to execute concurrently.Thus processes, whether they are system programs or application
programs, would be required to coordinate with one another to enforce mutual exclusion, with no support from the programming language or the OS. We
can refer to these as software approaches. Although this approach is prone to high
processing overhead and bugs, it is nevertheless useful to examine such approaches
to gain a better understanding of the complexity of concurrent processing.